
Intro:
It’s not surprising that SQL has been a mainstay for some time, and survey respondents have a strong preference for it as their chosen technology for data operations, with a majority of 51.52% endorsing it. For those transitioning from a software development background, especially one that is heavily reliant on SQL, adapting to Python dataframes, such as those offered by the Pandas library, can be challenging. Pandas is a popular Python library that simplifies data manipulation and analysis, offering advanced data structures and functions that are designed to handle structured data efficiently and intuitively.
The Sparks ecosystem enables distribute computing / multi-threading. So if you have larger data set working with Pandas might not be the best thing to work with. Also Sparks ecosystem uses in-memory computation which is faster than the disk-based computation used by Pandas.
Lets explore how to query dataset with SQL
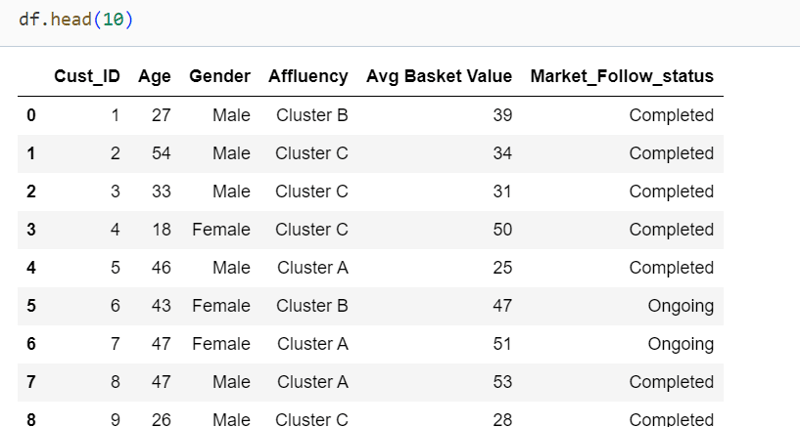
Generating Synthetic Data:
num_rows = 10000
num_columns = 5
data = {
‘Cust_ID’: np.arange(1, num_rows + 1), # Unique identifier for each customer
‘Age’: np.random.randint(18, 60, num_rows), # Customer Age
‘Gender’: np.random.choice([‘Male’, ‘Female’], num_rows), # Gender
‘Affluency’: np.random.choice([‘Cluster A’, ‘Cluster B’, ‘Cluster C’], num_rows), # Cluster group
‘Avg Basket Value’:np.random.randint(25, 60, num_rows),# Avg sale bucket
‘Market_Follow_status’: np.random.choice([‘Ongoing’, ‘Completed’], num_rows) # Follow-up status
}
df = pd.DataFrame(data)
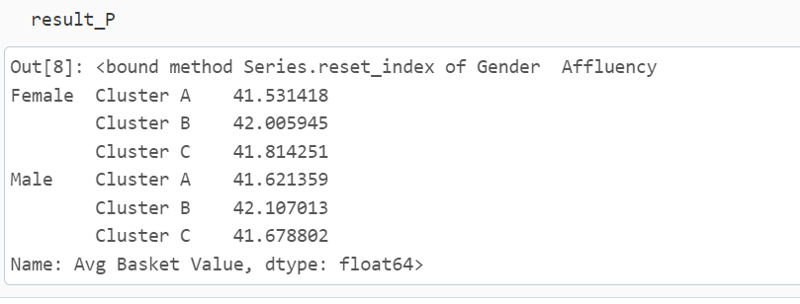
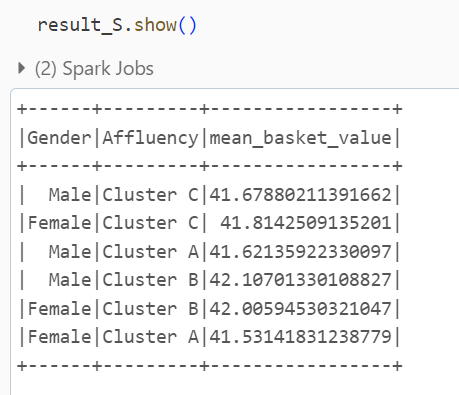
Now if I need to summaries the data by understanding the Avg Basket value by gender by cluster the pandas groupby
operation would be easy
Now to do similar operation but with SQL concept would be achieved by first converting the pandas data structure into a logical table.
Once you have a table available in memory then its like normal SQL to arrive at the same summarization
SELECT Gender, Affluency, AVG(`Avg Basket Value`) AS mean_basket_value
FROM df_view
GROUP BY Gender, Affluency
“””)
This approach would be no stranger to developers working with structured data in a familiar SQL-like manner.
Reference:
Stack OverFlow Survey
Spark SQL


{kind=link}
{kind=link}