
In this post, we will understand the 6’V of Big Data, review the Data Pipeline and Lambda architecture to understand the complexity of getting, storing, and processing the data, and then set up AWS services to ingest and store streaming data to perform real-time analytics. Let’s start.
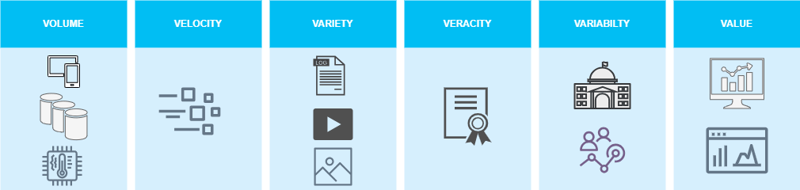
6’V of Big Data
The amount of data, the speed of produced data, and the diversity of data are common in the systems today, data is everywhere and we need to choose the right data sources to get the most accurate and valuable data. The 6V’s of Big Data shows us the challenges we need to face when creating Data Streaming Architecture with cost optimization and performance efficiency:
Volume: Gigabytes, Terabytes, Petabytes, and more are the amount of data we need to receive, store, and process.
Velocity: The data is produced all day, Eg 150K videos are uploaded to YouTube every minute, and 66K photos are shared on Instagram every minute. The data is coming at scheduled hours (batch), real-time (streaming), or both.
Variety: The data are files, fields, text, audio, video, and images. The data is structured, semi-structured, and unstructured.
Veracity: With many data sources the data could be incomplete, outdated, repeated, or not real, the quality of the data is essential to get the right insights.
Variability: The data could change, depending on the seasons, geopolitics events, or just add a new data source. You need to validate how often the structure or shape of your data changes and the side effect is the meaning the data changes also.
Value: The main purpose is to give value, describing what is happening, what could happen, and the opportunities identified. The data insights enable organizations to become data-driven.
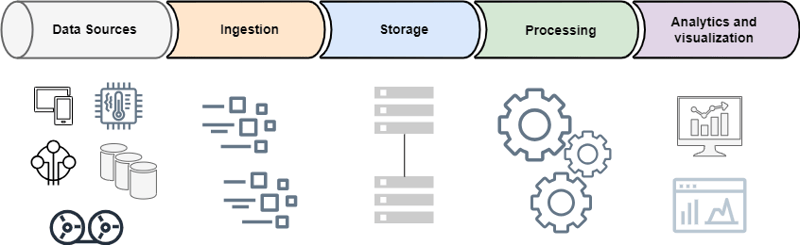
Data Pipeline
It is the building block for analytics solutions, it defines the layers and capabilities needed to optimize the ingestion, transformation, and storage of your analytics system. The layers are:
Data sources: Include databases, system logs, IoT signals, tape disks, and other kinds of storage systems with data related to your business. The data is structured, semi-structured, and unstructured.
Ingestion, move the data from external data sources to another location using tools like ETL, SDK, or middlewares, the tools depend on data type and workload requirements.
Storage, the data is stored temporarily or persistently in databases or object storage. The data is stored with format, partitioning, and compression for efficient storage and optimized querying.
Processing, to get performance efficiency and cost optimization, the data is cataloged for indexing and search, then processed to clean, complete, anonymization and enrich, and finally control access to enable confidentiality and integrity of the data.
Analytics and visualization provide descriptive and predictive analytics for discovering patterns and insights in data. This stage provides business decision-makers with graphical representations of analysis, making it easier to see the implications of the data.
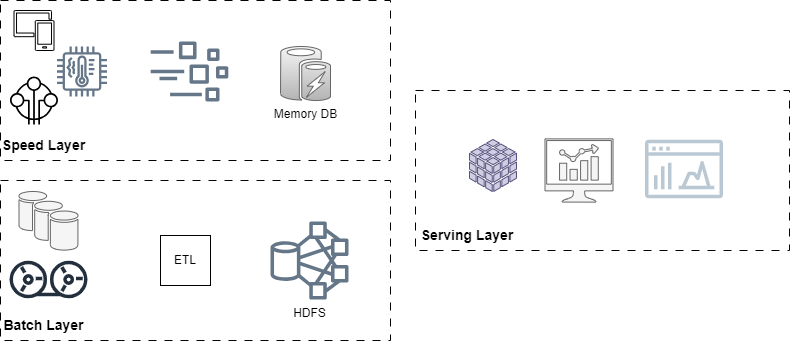
Lambda architecture
It is not a lambda function, it is a data-processing architecture designed to handle massive quantities of data coming from batch and real-time streams, and serving the data for user queries. This is a layered architecture to distribute the responsibilities and load to get better latency, throughput, and fault tolerance, the layers are.
Batch, all the data sources with historical data or transaction information with restrictions to get data in real-time are in this layer with ETL and execute a map-reduce programming model to filter and sort information and reduce (summarize) the data using a distributed and parallel system.
Speed, most recent information like events that occurred, online transactions, and streaming data are in this layer with capabilities to aggregate, partition, and compress the data in near real-time. The data could not be accurate or complete as a batch layer but it is available almost immediately.
Serving, the information from batch and speed layers are joined and stored on this layer to enable analytics tools to do predictive and prescriptive analytics executing queries over precomputed views.
In the next post, we will set up Kinesis Data Stream + Kinesis Firehose + S3 to ingest and store streaming data to perform real-time analytics.



{kind=link}
{kind=link}