
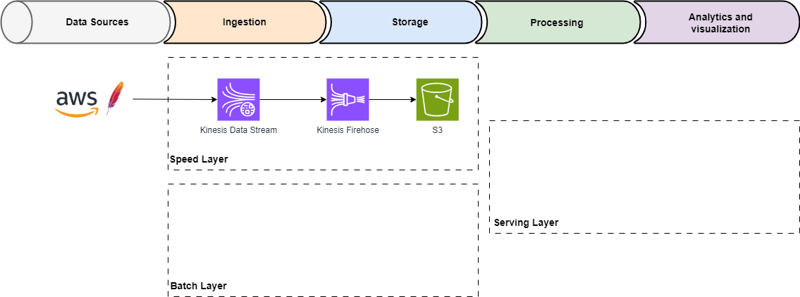
In a previous post, we studied the data streaming architecture basics, now we are going to set up AWS services to enable speed layer capabilities to ingest, aggregate, and store the streaming data. Each AWS service belongs to one or many stages of the data pipeline depending on their capabilities.
Kinesis Data Stream
Kinesis Data Stream is a serverless service with high throughput to ingest fast and continuous streaming data in real-time, it uses a shard to receive and store temporarily the data record in a unique sequence. A shard can support up to 1,000 RPS or 1 MB/sec writes and 2,000 RPS or 2 MB/sec read operations. The number of shards depends on the amount of data ingested and the level of throughput needed, more details about the capacity are here.
Go to Kinesis services and create a data stream using the on-demand capacity.
awsmeter JMeter Plugin
To produce streaming data we are going to use awsmeter, it is a JMeter plugin that uses AWS SDK + KPL (Kinesis Producer Library) to publish messaging on shards. You need an AWS access key and a data stream name. Find more details here.
The structure of this example message is using CloudEvents specification:
“specversion” : “1.0”,
“type” : “kinesis-data-stream”,
“source” : “https://github.com/JoseLuisSR/awsmeter”,
“subject” : “event-created”,
“id” : “${eventId}”,
“time” : “${time}”,
“datacontentcoding” : “text/xml”,
“datacontenttype” : “text/xml”,
“data” : “<much wow=“xml“/>”
}
S3
Use S3 to store streaming data and query the data with S3 Select. It is integrated natively with Kinesis Firehose and is a fully managed and regional service. Create a S3 bucket.
Kinesis Firehose
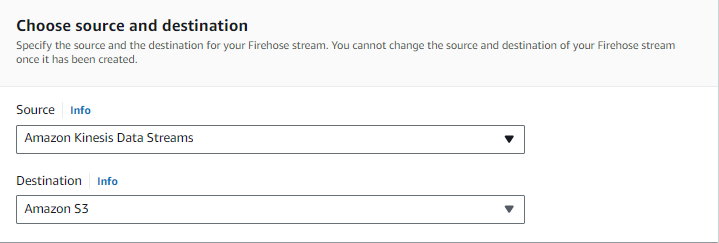
It is a streaming ETL solution to capture, transform, and load stream data into AWS data stores. Kinesis Firehose is a serverless service, fully managed by AWS, and automatically scales to support the throughput you need. To create a delivery stream you choose the source and destination.
For source choose Kinesis Data Stream, in the source setting section search the kinesis data stream you created.
For Destination choose S3, in the destination setting section search S3 bucket you created.
Enable Dynamic partitioning for efficient query optimization.
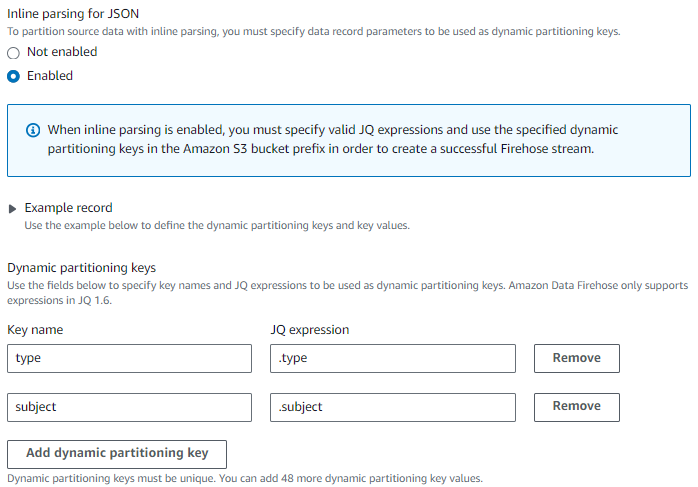
Enable Inline parsing for JSON to use the Kinesis Data Firehose built-in support mechanism, a jq parser, for extracting the keys from messages for partitioning data records that are in JSON format. Specify the key name and JQ expression as below:
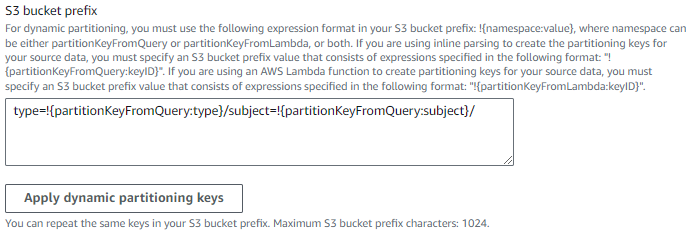
In the S3 bucket prefix section, choose Apply dynamic partitioning keys to generate partition key expressions. To enable Hive-compatible style partitioning by type and source, update the S3 bucket prefix default value with type= and source=.
In the S3 bucket error output prefix box, enter kdferror/. It will contain all the records that the Kinesis Data Firehose is not able to deliver to the specified S3 destination.
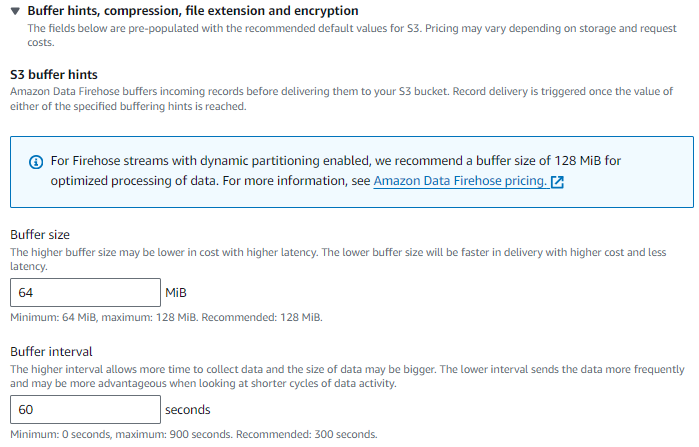
In the delivery stream setting section, expand the Buffer hints, compression, and encryption section.
For Buffer size, enter 64.
For Buffer interval, enter 60.
Kinesis Data Firehose buffers incoming streaming data to a certain size and for a certain period before delivering it to the specified destinations (S3). For a delivery stream where data partitioning is enabled, the buffer size ranges from 64 to 128MB, with the default set to 128MB, and the buffer interval ranges from 60 seconds to 900 seconds.
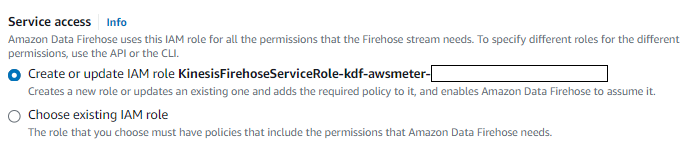
To Kinesis Firehose can access S3 need to use IAM roles with the permissions needed, on the advance settings choose existing IAM role
Review the stream configuration, and then choose Create delivery stream
S3 Select
Check your S3 Bucket to see if the data is stored on the folders of type and subject that are the dynamic partitions we configured. Choose one file, go to actions, and select the Query with S3 Select option.
Conclusion
In this post you have provisioned and set up aws services to enable a data streaming architecture solution, you have done the following:
Created Kinesis Data Stream.
Set up awsmeter to generate streaming messages.
Created a Kinesis Data Firehose stream and connected the Kinesis data stream to it.
Configured dynamic partitioning on the Kinesis Data Firehose delivery stream.
Delivered data to Amazon S3.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}