
This quick rundown explores Ollama and my experience with local Language Model Microservices (LLMs) and their uses in inference-based tasks. Among local LLM options, LMStudio was my first encounter, finding it easy to use. Yet, I’ve been intrigued by Ollama for its simplicity and adaptability.
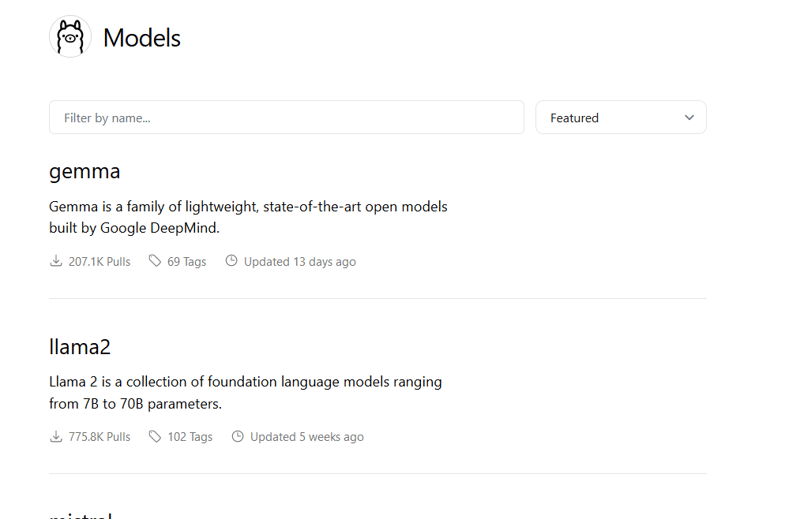
In a nutshell, Ollama has its own collection of models that users can access. These models can be downloaded to your computer and interacted with through a simple command line. Alternatively, Ollama offers a server for inference, usually at port 11434, allowing interaction via APIs and libraries like Langchain.
Currently, Ollama offers a variety of models, including embedding models.
Getting started with OLLAMA
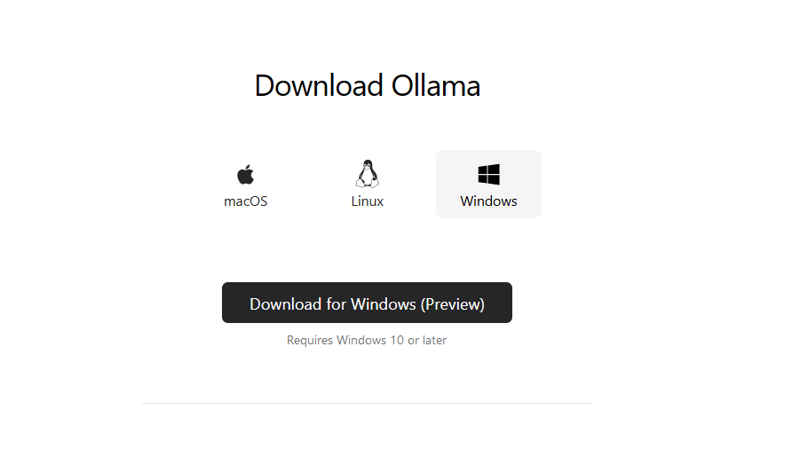
To start using Ollama, download the version for your operating system.
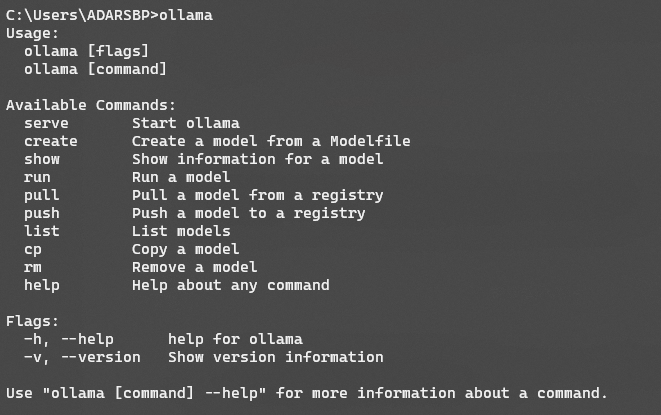
After installation, check if it’s working by typing ‘ollama’, which should show a help menu.
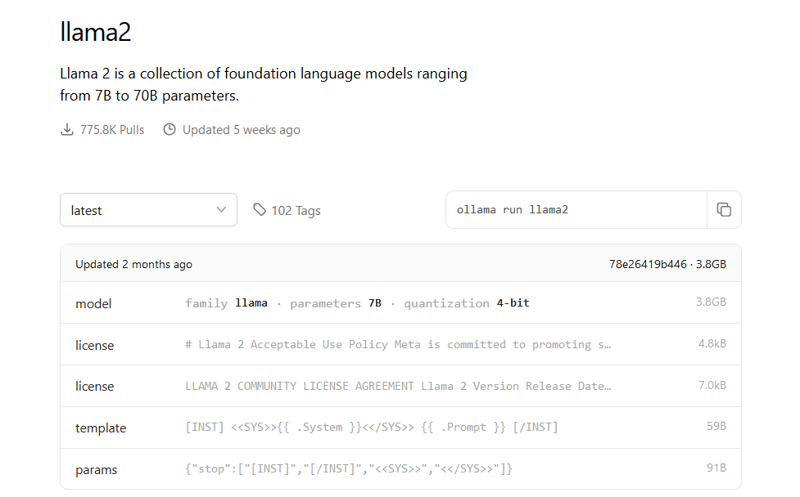
To make use of any model, the initial step involves “pulling” it from Ollama, which is akin to downloading an image from Dockerhub (assuming you’re acquainted with that platform) or a service like Elastic Container Registry (ECR). Additionally, Ollama comes pre-loaded with several default models, one of which is llama2, recognized as Facebook’s open-source LLM.
To Download the model that would like to interact use the command to download , Assume if you want to download llama2
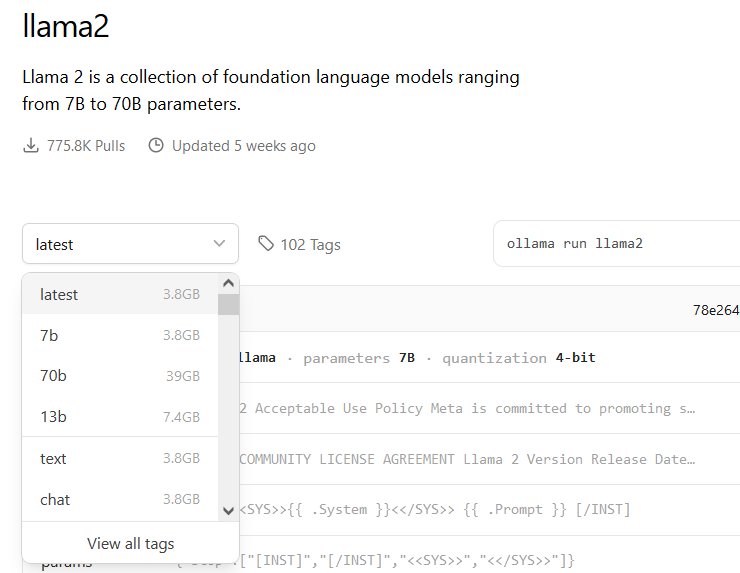
You can also check the different version of model and download which is required according to your usecase.
Once the download is complete, you can check to see whether the model is available
Now you can run the model in your local machine
Now you can ask any questions and the response speed will be based on your system configurations and model
The precision of the responses may not always be optimal, but this can be mitigated by selecting different models or employing techniques such as fine-tuning. Alternatively, implementing a RAG-like solution independently could enhance accuracy.
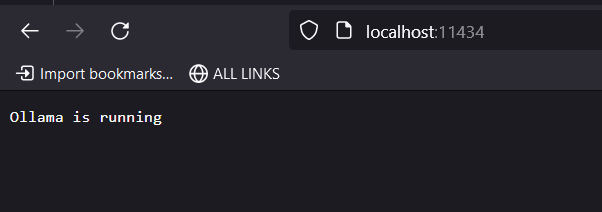
If you examine Llama’s inference server, you’ll notice that there are programmatic methods available to access it by connecting to port 11434.
Now this could be extended more to integrate with langchain and create a application based on your usecase.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}