
Suppose you have a need to run high and low priority jobs. High priority jobs usually have some service level agreements for time-to-start, and should be run ahead of low priority jobs.
You can take advantage of a couple of AWS Batch features to create a nice environment to meet this need. First I’ll cover the relevant features we will take advantage of, then present the architecture, what you should pay attention to, and why I configured some features the way I did.
Job queues and compute environments
An AWS Batch job queue (JQ) is an always on queue you can send job requests to. An AWS Batch compute environments (CE) represents the minimum, maximum, and type of compute resources Batch can scale for your jobs.
You can attach one or more CEs to a job queue, and the JQ willwill scale the compute environment(s) based on the number and size of jobs in the queue. Multiple compute environments attached to a job queue filled up with jobs in order. I.e. jobs will be placed on the first CE until it is at maximum capacity, then the next until it is full, then the next, etc., etc.
Compute environments can be attached to more than one job queue. If multiple job queues attached to the same compute environment, they will get evaluated in the order of their defined priority, with higher priority JQs being evaluated for job placement before those with lower priority.
Leveraging these relationships for our high and low priority use case:
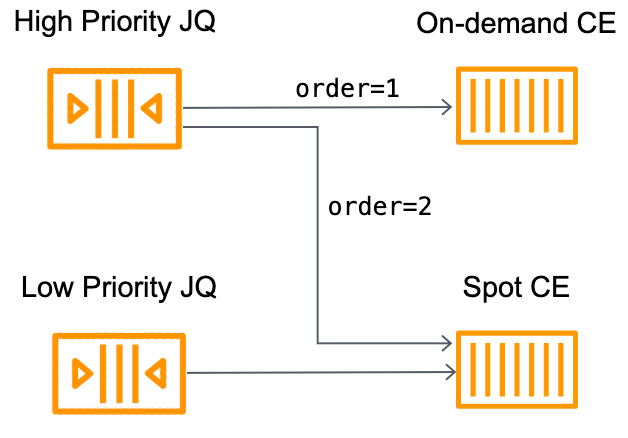
Create two compute environments, one that is On-Demand and the other that leveraged Spot capacity.
a. The On-Demand CE should be sized appropriately to meet your high-priority job SLA.
b. The Spot CE should be a higher capacity BUT should only be leveraged for opportunistic work that have no SLA.
Create two job queues, one high-priority and one low-priority.
Attach the low-priority job queue to the Spot CE.
Attach the high-priority job queue to both CEs, with the On-Demand CE before the Spot CE.
The architecture is illustrated in the following figure.
Why this works:
High priority jobs will have their own pool of on-demand resources to meet SLA. You should size your minimum and maximum capacity to your expected SLAs for job start time. You can change this values over time to meet SLAs while optimizing for cost.
The high priority JQ is also attached to the Spot CE. If the on-demand CE is full, jobs have the opportunity to run on the Spot CE, giving you a potential pressure relief when there are spikes in demand.
Note: watch for Spot interruptions for high priority jobs! If these jobs fail regularly on Spot, then you are doing more harm than good and should only leverage on-demand resources.
Low priority jobs run on low-cost infrastructure as it becomes available.
While the above is a workable solution, you can make several improvements by leveraging fair share scheduling policies.
Job queue fair share policies
Job queues are able to prioritize scheduling of jobs from one category over others using fair share scheduling policies. I wrote a deep-dive into fair share scheduling in this blog post but to summarize: a share policy on a job queue allows you to tag a job with a share ID, such as high-priority, and tell the scheduler to preference these jobs over others at some proportional value such as 2:1 or 100:1 or even more. Share policies also allow you to reserve a portion of the maximum capacity of a compute environment for share IDs that have not been seen before.
The issue with our first architecture is JQ priority ordering is not strict. Meaning that the scheduler evaluates the head of all of the ordered job queues and may place jobs from each queue on free resources. It does not drain the highest priority queue of all work before evaluating lower priority job queues.
Hence a high priority job may not always get scheduled ahead of a low priority job.
You can increase the likelihood that a high priority job placement on the Spot CE by creating a low-priority job queue with a scheduling policy that has:
A compute reservation to set aside 10% to 20% of the maximum capacity for jobs with unseen share IDs
A weight factor for high priority jobs of less than one to allow preference of these jobs over low priority jobs
Note that everything else is the same, and that the high priority JQ does not have a scheduling policy, just the lower priority one. The modified diagram looks like the following diagram
The modified setup works as before with high priority jobs going to the on-demand CE first before sending jobs to the Spot CE. Low priority jobs go to the Spot CE but do not fill up the CE to max capacity, leaving some room for high-priority jobs to start immediately. Finally, the lower weight factor of high-priority jobs will increase the likelihood that these jobs will get placed before the low priority ones as jobs finish and resources free up.
Hope this practical example helps you, let me know in the comments if you have questions!




{kind=link}