
Fake News ระบาด
ในยุคนี้อินเทอร์เน็ตผู้คนมากมายต่างแชร์ข่าวสารกับทุกวินาที แต่หารู้ไม่ข่าวบางชิ้นที่พวกเขาแชร์ อาจเป็นเรื่องแต่งขึ้นมาโดยไม่มีมูล วันนี้ผมจะพาไปรู้จักกับ AI ตัวหนึ่งที่สามารถกรองข่าวได้ว่า ข่าวไหนที่เราเจอเป็นจริงและข่าวไหนเป็นเท็จกัน
CNN Machine Learning
CNN ตัวย่อของ Convolutional Neural Network โครงข่ายประสาทเทียม ประเภทหนึ่งที่ได้รับการออกแบบมาเพื่อวิเคราะห์ข้อมูลเชิงพื้นที่ เช่น ภาพ และ วิดีโอ ที่มีประสิทธิภาพสูง สามารถนำไปแยก จำแนก และตรวจสอบสิ่งของหรือสิ่งมีชีวิตได้ เช่น สุนัข รถยนต์ รูปท้องฟ้า และเพิ่มความคมชัดของภาพได้ เป็นต้น
หลักการทำงาน
CNN ทำงานโดยใช้ เลเยอร์ (Layer) หลายชั้น แต่ละชั้นประกอบด้วย ฟิลเตอร์ (Filter) ซึ่งทำหน้าที่เลื่อนไปบนข้อมูลภาพเพื่อดึงคุณลักษณะเฉพาะ ฟิลเตอร์เหล่านี้เรียนรู้จากข้อมูลตัวอย่าง (training data) โดยปรับน้ำหนัก (weight) ของตัวเองให้เหมาะสม
งั้นเรามาเริ่มสร้างและฝึกสอน AI ตัวนี้ของเรากันเลย
เตรียม Dataset หรือ ชุดข้อมูล
ข้อมูลนี้คือตัวอย่างของข่าวที่หามาจากอินเทอร์เน็ต
https://drive.google.com/file/d/1XoHoUjZtLQ6gh_CPv9_igtZoEsdkgq3t/view
Import Library
เราจะ Import Library มา 4 ตัวคือ NumPy เรียกการดำเนินการทางคณิตศาสตร์ , Pandas เรียก Dataset ที่เรานำเข้า , TensorFlow วิเคราะห์ข้อมูลและสร้างโมเดลจากข้อมูล , SkLearn ไว้ฝึกโมเดลในการวิเคราะห์ข่าว
import pandas as pd
import json
import csv
import random
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
from tensorflow.keras.utils import to_categorical
from tensorflow.keras import regularizers
import pprint
import tensorflow.compat.v1 as tf
from tensorflow.python.framework import ops
from sklearn.model_selection import train_test_split
from sklearn import preprocessing
tf.disable_eager_execution()
# Reading the data
data = pd.read_csv(“news.csv”)
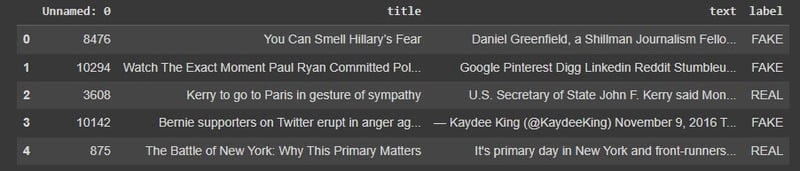
data.head()
Output ที่เราจะได้จะเป็นแบบนี้
เรามีตาราง Unnamed อยู่ซึ่งเราไม่ต้องการ เราจะลบออกไปโดย Code นี้
data.head(5)
หลังจากได้ตารางแล้ว จะแปลงตารางและข้อมูลเป็นตัวเลขโดย Code นี้
le = preprocessing.LabelEncoder()
le.fit(data[‘label’])
data[‘label’] = le.transform(data[‘label’])
Code นี้จะกำหนดพวกตัวแปรต่างๆ จากข้อมูลเพื่อให้ AI ของเราทำงานง่ายขึ้น
max_length = 54
trunc_type = ‘post’
padding_type = ‘post’
oov_tok = “<OOV>”
training_size = 3000
test_portion = .1
Tokenization (การแบ่งแยก) กระบวนการนี้แบ่งข้อความต่อเนื่องขนาดใหญ่เป็นหน่วยหรือโทเค็นที่แยกจากกัน โดยพื้นฐานแล้ว ที่นี่เราใช้คอลัมน์แยกกันเป็นฐานเวลาเป็นไปป์ไลน์เพื่อความแม่นยำที่ดี ด้วย Code นี้
text = []
labels = []
for x in range(training_size):
title.append(data[‘title’][x])
text.append(data[‘text’][x])
labels.append(data[‘label’][x])
tokenizer1.fit_on_texts(title)
word_index1 = tokenizer1.word_index
vocab_size1 = len(word_index1)
sequences1 = tokenizer1.texts_to_sequences(title)
padded1 = pad_sequences(
sequences1, padding=padding_type, truncating=trunc_type)
split = int(test_portion * training_size)
training_sequences1 = padded1[split:training_size]
test_sequences1 = padded1[0:split]
test_labels = labels[0:split]
training_labels = labels[split:training_size]
ทีนี้เราจะต้องไปดาวน์โหลด Word Embedding กระบวนการนี้ช่วยให้คำที่มีความหมายใกล้เคียงกัน มีการแทนค่าในรูปแบบที่คล้ายคลึงกัน ในที่นี้ แต่ละคำจะแสดงเป็นเวกเตอร์ที่มีค่าเป็นจำนวนจริง ภายในพื้นที่เวกเตอร์ที่กำหนดไว้ล่วงหน้า
https://drive.google.com/file/d/1ekbxlI_GdF3H_XHS8U2Csj5q5AhNXhMp/view
หลังจาก Download ตัว Word Embedding มาแล้ว เราก็ต้องเรียกใช้มันด้วย Code นี้
with open(‘glove.6B.50d.txt’) as f:
for line in f:
values = line.split()
word = values[0]
coefs = np.asarray(values[1:], dtype=’float32′)
embeddings_index[word] = coefs
# Generating embeddings
embeddings_matrix = np.zeros((vocab_size1+1, embedding_dim))
for word, i in word_index1.items():
embedding_vector = embeddings_index.get(word)
if embedding_vector is not None:
embeddings_matrix[i] = embedding_vector
นำเข้า AI Model
เราจะใช้ตัว TensorFlow Model มาใช้วิเคราะห์ Fake News ด้วย Code นี้
tf.keras.layers.Embedding(vocab_size1+1, embedding_dim,
input_length=max_length, weights=[
embeddings_matrix],
trainable=False),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Conv1D(64, 5, activation=’relu’),
tf.keras.layers.MaxPooling1D(pool_size=4),
tf.keras.layers.LSTM(64),
tf.keras.layers.Dense(1, activation=’sigmoid’)
])
model.compile(loss=’binary_crossentropy’,
optimizer=’adam’, metrics=[‘accuracy’])
model.summary()
เริ่มทำการ Train Model โดย Code นี้
training_padded = np.array(training_sequences1)
training_labels = np.array(training_labels)
testing_padded = np.array(test_sequences1)
testing_labels = np.array(test_labels)
history = model.fit(training_padded, training_labels,
epochs=num_epochs,
validation_data=(testing_padded,
testing_labels),
verbose=2)
และสุดท้ายเราจะให้ AI เริ่มจับว่าข่าวไหนเป็นจริงบ้างจากข้อมูลที่ให้ไปเมื่อตอนต้นโดย Code นี้
X = “Karry to go to France in gesture of sympathy”
# detection
sequences = tokenizer1.texts_to_sequences([X])[0]
sequences = pad_sequences([sequences], maxlen=54,
padding=padding_type,
truncating=trunc_type)
if(model.predict(sequences, verbose=0)[0][0] >= 0.5):
print(“This news is True”)
else:
print(“This news is false”)
Output ที่ได้
updates=self.state_updates,
This news is True
สรุปผล
ตัว Model ทำงานได้ดีถึง 90% แต่ยังมีข้อจำกัดบางอย่างอยู่บ้างเช่น โมเดลอาจมีอคติจากชุดข้อมูลที่ใช้ฝึกโมเดล แต่ทั้งนี้ทั้งนั้น Model นี้สามารถนำไปพัฒนาต่อได้อีก
ที่มาข้อมูล : https://www.geeksforgeeks.org/fake-news-detection-model-using-tensorflow-in-python/


{kind=link}
{kind=link}