

But first — Inheritance
Inheritance in Postgres allows you to create a table that inherits from another table. This feature can be used to model hierarchical data within the database. A child table inherits all columns from the parent table but can also have additional columns.
Example: Build a data model for cities and population data. Each country has many cities but only 1 capital. A common access pattern that your model should be able to support is — Get all capitals and their population data!
One way to solve this problem:
A common approach one could take is the following (add an is_capital column to your schema).
name varchar(100),
country_iso_code varchar(10),
population bigserial,
is_capital boolean,
primary key (name)
);
insert into cities (name, country_iso_code, population, is_capital) values
(‘New Delhi’, ‘IN’, 10927986, true),
(‘Pune’, ‘IN’, 3124458, false),
(‘Bangkok’, ‘TH’, 5104476, true),
(‘Almaty’, ‘KZ’, 1977011, false),
(‘Stockholm’, ‘SE’, 1515017, true),
(‘Washington, D.C.’, ‘US’, 689545, true);
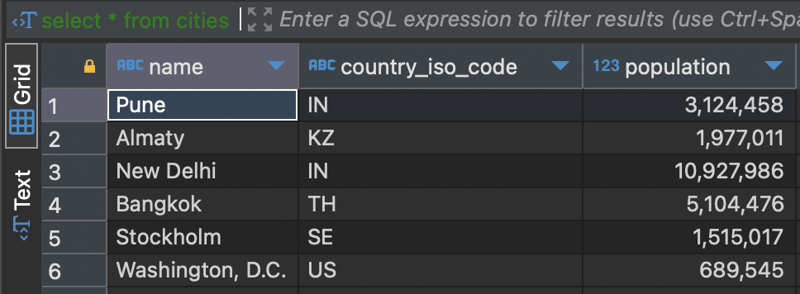
select * from cities where is_capital = true;
Another way to solve this problem (using inheritance)
name varchar(100),
country_iso_code varchar(10),
population bigserial,
primary key (name)
);
create table capitals (
— You can define additional columns here if you want to
) inherits (cities);
insert into cities (name, country_iso_code, population) values
(‘Pune’, ‘IN’, 3124458),
(‘Almaty’, ‘KZ’, 1977011);
insert into capitals (name, country_iso_code, population) values
(‘New Delhi’, ‘IN’, 10927986),
(‘Bangkok’, ‘TH’, 5104476),
(‘Stockholm’, ‘SE’, 1515017),
(‘Washington, D.C.’, ‘US’, 689545);
A select * from cities returns data from all tables (base + inherited).
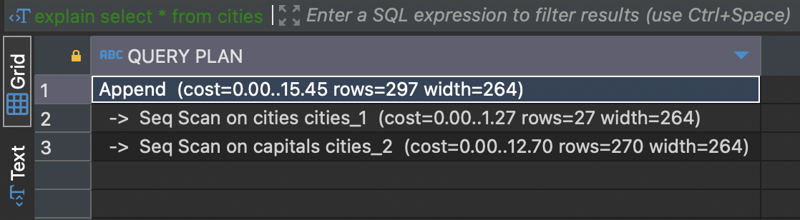
The explain command shows that it does a scan on both the tables.
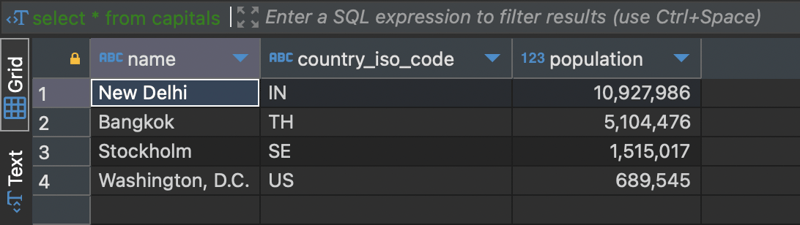
A select * from capitals returns data in the capitals table only.
The explain command shows that it does a scan on the capitals table only, potentially improving query performance.
Partitioning
Partitioning in postgres is based on/backed by inheritance under the hood. Partitioning in PostgreSQL involves splitting a large table into smaller, more manageable tables, while still treating them as a single table. This can significantly improve performance for large datasets by reducing index size, enhancing query performance, and making bulk operations like loads and deletes more efficient. This can also become the base for your archival process.
The idea is to partition/split a table by a partition key and while querying, supply the partition key in the where clause such that postgres only queries the required partition thereby improving query performance.
Example: We have a portfolio management application. It stores EOD stock prices for a large number of securities. Over time, this table will become bulky and this can deteriorate performance. Also, how do you create an archiving strategy to move/delete old data from this table?
id varchar(255),
security_id varchar(255),
price numeric,
business_date date
) partition by range (business_date);
— Create partitioned tables. In postgres, this has to be done manually 🙁
— Range (Inclusive, Exclusive)
create table security_prices_march_2024 partition of security_prices for values from (‘2024-03-01’) to (‘2024-04-01’);
create table security_prices_april_2024 partition of security_prices for values from (‘2024-04-01’) to (‘2024-05-01’);
create table security_prices_may_2024 partition of security_prices for values from (‘2024-05-01’) to (‘2024-06-01’);
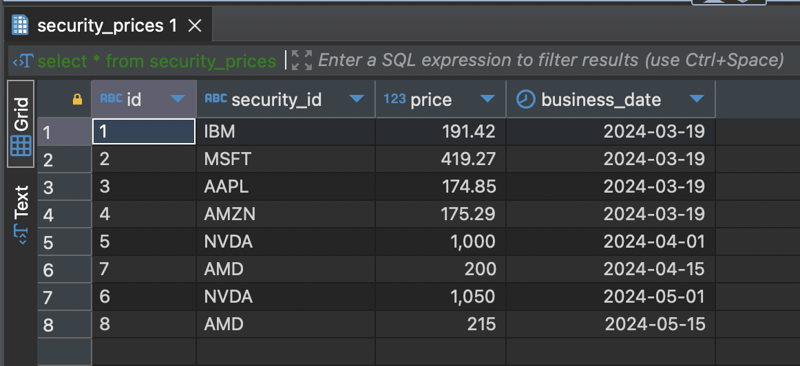
insert into security_prices (id, security_id, price, business_date) values
(‘1’, ‘IBM’, 191.42, ‘2024-03-19’),
(‘2’, ‘MSFT’, 419.27, ‘2024-03-19’),
(‘3’, ‘AAPL’, 174.85, ‘2024-03-19’),
(‘4’, ‘AMZN’, 175.29, ‘2024-03-19’),
(‘5’, ‘NVDA’, 1000, ‘2024-04-01’),
(‘6’, ‘NVDA’, 1050, ‘2024-05-01’),
(‘7’, ‘AMD’, 200, ‘2024-04-15’),
(‘8’, ‘AMD’, 215, ‘2024-05-15’);
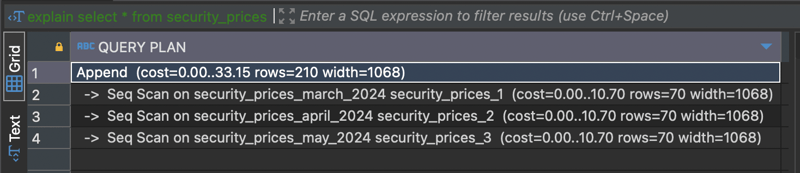
A select * from security_prices returns data from all partitioned tables.
The explain command shows that it does a scan on all the tables.
But, what if you mention the partition key in the where clause?
A select * from security_prices where business_date = ‘2024–03–19’ returns the correct data:
And, the explain command shows that it queried the march table only!
The example above is an example of Range Partitioning — Partitioning your tables by ranges.
Now that you have separate tables, you could drop or move data safely from old tables (Archiving!)
Note — In the above example, I have not defined a primary key. In PostgreSQL, if you do not explicitly define a PK for a table, then the table will not have a PK (lookup ctid in postgres to get more information on this). If you choose to add a PK to a partitioned table (which I suggest you should), the PK must include the partition key. In our case, since business_date is the partition key, if you were to add a PK, it would need to include business_date along with other columns to ensure uniqueness across all partitions. For instance, you could define a composite primary key that includes both id and business_date: CREATE TABLE security_prices (…, PRIMARY KEY (id, business_date);. In this case, you can create a composite key (which will include both Id and BusinessDate) using @ Embeddable and embed it in your entity using @ EmbeddedId (see — Composite keys and JPA)
Now, let’s map this entity to our spring data jpa application:
spring.datasource.url=jdbc:postgresql://localhost:5432/security-service
spring.datasource.username=postgres
spring.datasource.password=password
spring.jpa.hibernate.ddl-auto=validate
@Data
@EqualsAndHashCode(of = {“id”})
public class SecurityPrice {
@Id
/*
IMP – How do you map an entity with no primary key in spring data jpa?
JPA expects every entity to have an @Id column!
You cannot use the internal ctid postgres column here.
But, you can use any business key as an Id in JPA even though it’s not a primary key in the database
*/
private String id = UUID.randomUUID().toString();
private String securityId;
private BigDecimal price;
private LocalDate businessDate;
}
public interface SecurityPriceJpaRepository extends JpaRepository<SecurityPrice, String> {
Optional<SecurityPrice> findBySecurityIdAndBusinessDate(String securityId, LocalDate businessDate);
}
public class SecurityPriceService {
private final SecurityPriceJpaRepository securityPriceJpaRepository;
public SecurityPriceService(SecurityPriceJpaRepository securityPriceJpaRepository) {
this.securityPriceJpaRepository = securityPriceJpaRepository;
}
@Transactional
public String createSecurityPrice(SecurityPriceRequest securityPriceRequest) {
String securityId = securityPriceRequest.securityId();
LocalDate businessDate = securityPriceRequest.businessDate();
Optional<SecurityPrice> existingPriceOptional =
securityPriceJpaRepository.findBySecurityIdAndBusinessDate(securityId, businessDate);
SecurityPrice securityPrice = new SecurityPrice();
securityPrice.setSecurityId(securityId);
securityPrice.setPrice(securityPriceRequest.price());
securityPrice.setBusinessDate(businessDate);
existingPriceOptional.ifPresent(price -> securityPrice.setId(price.getId()));
securityPriceJpaRepository.save(securityPrice);
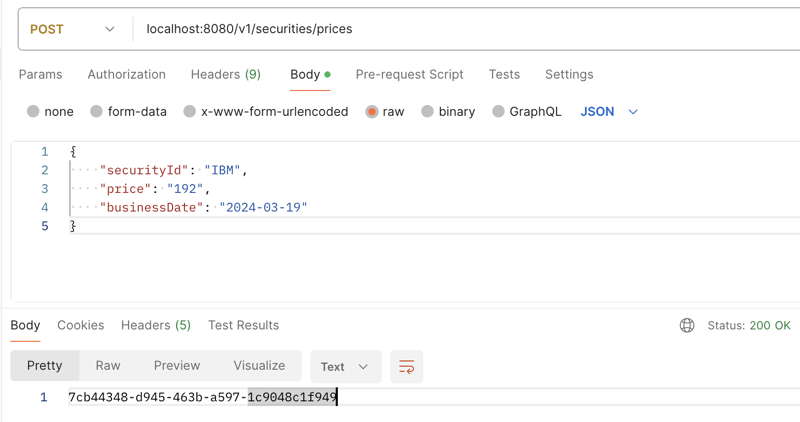
return securityPrice.getId();
}
}
@RequestMapping(“/v1/securities”)
public class SecurityPriceController {
private final SecurityPriceService securityPriceService;
public SecurityPriceController(SecurityPriceService securityPriceService) {
this.securityPriceService = securityPriceService;
}
@PostMapping(“/prices”)
public ResponseEntity<String> createPriceEntry(@RequestBody SecurityPriceRequest securityPriceRequest) {
return ResponseEntity.ok(securityPriceService.createSecurityPrice(securityPriceRequest));
}
}
Running the explain select * from security_prices with a business date of 2024–03–19 shows that it queries the march table only!
List Partitioning
Another type of partitioning that is commonly used is List partitioning.
Example: You have an ecommerce application that generates a lot of orders. An order transitions through the following states — (CREATED, SHIPPED, DELIVERED, CANCELLED, ARCHIVED). A cron runs every night that marks DELIVERED (delivered > a month ago) and CANCELLED orders as ARCHIVED. Archived orders are only needed for audit/reporting purposes. Keeping these orders in the orders table will impact the performance of our application.
Let’s come up with a partitioning scheme for this problem:
order_id varchar(255),
user_id varchar(255),
total numeric,
order_items jsonb,
status varchar(255)
) partition by list (status);
create table active_orders partition of orders for values in (‘CREATED’, ‘SHIPPED’, ‘DELIVERED’, ‘CANCELLED’);
create table archived_orders partition of orders for values in (‘ARCHIVED’);
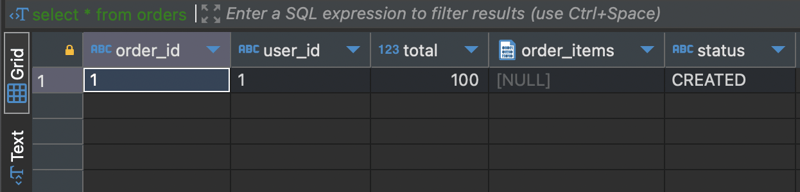
Let’s add a new order
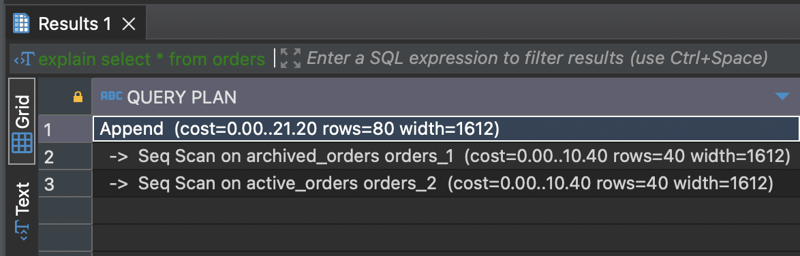
select * from orders;
The order will automatically move into the archived_orders table. In your application, always specify the status in the where clause. This way, your application will almost always access the active orders table which will have less numbers of orders at any given point of time boosting performance!

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}