
Hello everyone! If you’ve been following my post for the past week, I would like to announce that I need to pause my AI Chess project since a new exciting offer just came to me and I need to learn a new technology! So, this series would be about image enhancement, which basically means changing an image from low-resolution to a high-resolution(usually called super resolution, or SR for short). I am doing this series as a way to both teach you guys about it and also strengthen my understanding of it. So, without further ado, let’s jump right into it
Assumptions
I would first of all start with the assumption that you know what a traditional neural network is, which is the basic of the convolutional neural network but with further tweaks and adjustments for a different task. If you don’t know what a neural network is, I would highly recommend this video series on YouTube by 3Blue1Brown to learn about it.
Why CNN
Now that that’s out of the way, why not just use regular neural network with nodes in layers and weights connecting nodes of different layers? Wouldn’t that achieve similar result?
Enormous computing power
A normal colored image of dimension 1000×1000 pixels, consist of 3 channels, each representing the color red, blue and green. So you say, okay now we can have 3x1000x1000 nodes in our input layer. Okay, that’s fine. But, what about the hidden layer. Let’s say the first hidden layer has 100 nodes. The total weights would be 3x1000x1000x100= 300000000 weights, and that’s just the connection between the input layer and the first layer! As a result of that, the image processing would be so slow that for example if we’re building an image detection model using videos from cameras, the videos would lag noticeably.
To learn more complex patterns in images, the neural network would need more hidden layers and way more nodes in each layer, so the traditional neural network or artificial neural network (ANN) would not quite cut it for image related tasks.
Convolution operation
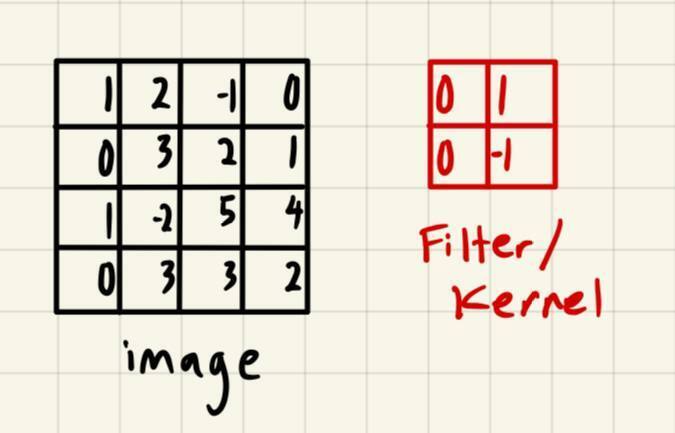
So how does CNN differ from ANN? ANN perform convolution operation on images instead of weights and nodes architecture in ANN. The basic idea of it is that you have a filter (or kernel) of fixed dimension, ranging from 1×1 to 5×5. Let’s start with an example of an image of size 4×4 pixel (yes, I know it’s pretty small) for simplicity’s sake, and a filter of size 2×2:
For now, let’s just put simple random numbers inside the kernel and image.
Convolution operation usually start by sliding the kernel over the image array and the dot product of the overlapped array is calculated and put in an output array:
Then, the process is repeated by sliding the kernel one step to the right (or any step actually, depend on your architecture) and repeat the process until the whole output array is filled. After all the element in the row is completed, slide down and to the left of the next row to continue the process:
Of course we give the kernel a random value for this example, but in an actual CNN architecture, the values inside the kernels are the weights that need to be adjusted based on training data by doing the process similar in ANN which is forward propagation, calculating the loss using suitable loss function, the performing backpropagation to update the weights and biases.
Small problems
However, there is a few problem with this. First, the output array dimension is significantly reduced from the original input image, resulting in many information loss over many iterations of it.
Also, not all pixel in the image array is used the same number of time for convolution operation. For example, the top left corner pixel only undergo convolution operation once which is the first one. As a result, the feature that may be in the corner may be given less importance, which may not be true for all images in the world right.
To combat this, a concept called padding is introduced
Padding
Padding is added to image array by putting 0’s all over the frame of the array like this:
With this, the convolution operation would capture feature more effectively and the output array size would be bigger so it solve both the problems we discussed above.
Overfitting
However, we may encounter another problem which is overfitting, where our model do great with training data but but horribly on data it has never seen before. To counter this, an optional layer is added after the convolutional layer which is called the pooling layer
Pooling
Pooling works by having a fixed size array like kernel, but instead of having values inside them and doing dot product on overlapped part of the image array, we perform a specific operation depend on the type of pooling. There’s 2 main types of pooling, the max pooling and average pooling
1. Max pooling
This is performed by just taking the maximum value of the overlapped image array with the pooling array, and store that value in the output array.
2. Average pooling
This is also kind of similar to max pooling, but instead of the maximum value, the average of all the overlapped elements is stored in the output array.
Activation functions
Finally, in CNN we also use activation functions like in ANN to introduce non-linearity. Common activation functions are ReLu and sigmoid.
Putting it all together
So in a CNN, we first have an input layer of 3 channels for images with colors, then we have the first layer which consist of the convolutional layer where the convolution operation with kernels is performed, and an optional pooling layer, then the second layer and so on until the output layer.
Conclusion
So that wraps up the basic of CNN or Convolutional Neural Network. If you would like to learn more, I highly recommend this video series by CodingLane, highly underrated in my opinion!
That’s all from me for this post, stay tune for more and happy coding!




{kind=link}
{kind=link}
{kind=link}